@radekmieBy Radosław Miernik · Published on · Comment on Reddit
Whether you’re working in a small, medium, or massive company, you’ve almost certainly encountered Jira or any other “issue tracker” already. Many people sincerely hate them for thousands of reasons, and I was one of them for a long time. On the one hand, because it’s surprisingly slow for what it’s doing…
On the other, because it’s where the problems come from. Descriptions are not in-sync with the discussions, priorities are not valid since ever, the backlog is a trash pile accumulated throughout the years, and the refactoring task you created four sprints ago is not even in the tenth sprint from now. Been there, done that.
The former are apparent problems of the software itself, but the latter are not, and we should not blame it for that. No malicious Atlassian employees are messing up with our tasks for fun or profit – it’s all on us. I wanted to make it better, but others didn’t care. Or, to state the problem, didn’t get time for that.
And then I got admin rights…
It’s huge. The PDF documentation for Jira Software Data Center and Server 9.7 (there’s no PDF version for the Cloud version) is 538 pages long. Of course, it’s nicely formatted, contains screenshots, and includes an installation guide, but it’s easily in the top ten largest pieces of documentation I’ve ever seen.
I was sceptical at first – how the hell could I make any sense of it? Nobody felt like changing anything there for a while now; maybe there’s a reason for that? In the end, I heard of “Jira ninjas” and thought it was an inside joke, but perhaps it’s true that you must enter a slightly different state of mind to handle it?
I asked a couple of experienced people for an introduction, but everyone said the same thing: “I can help you with X and Y”. It’s not bad per-se, but it looks like everyone knows only as much as they need, and nobody was really interested to learn more just for the sake of it. (Maybe I’m the weird one here.)
I wanted to change something, both to make my own life easier and to see how hard it actually is. For starters, I decided to organize our workflow. At first, I wanted to change just two things – improve wording in transitions and make the graph accessible for everyone on the team. Here’s what I started with:
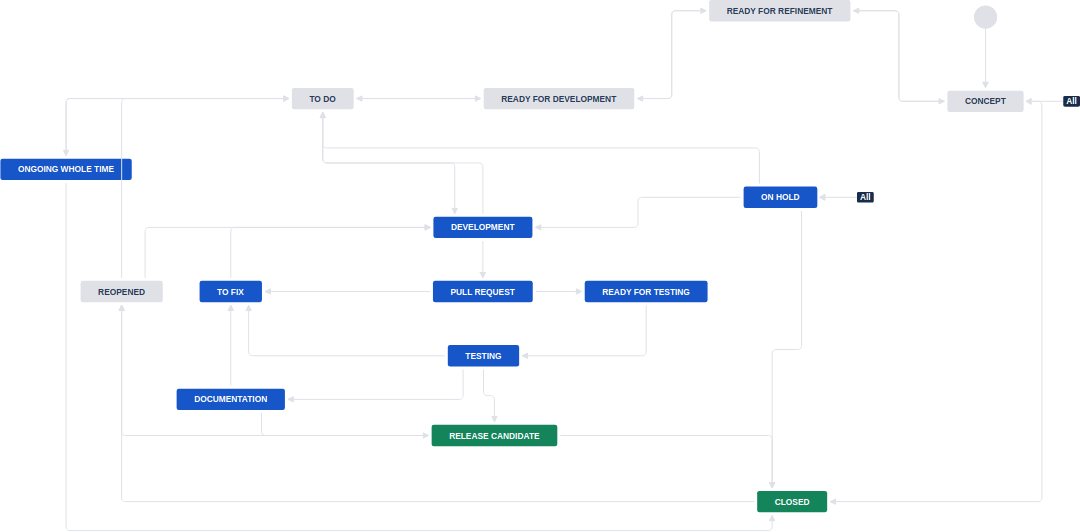
There’s no point in zooming in – it was a mess. The transitions (arrows) were all around the place, and it was hard to know what would (or should) happen next. As I was already looking into it, I brainstormed with the team on whether we needed all of it in the first place. As a result, we’ve decided to simplify it slightly at the beginning, and instead of having multiple pre-TO DO states, we have one. Here’s the result:
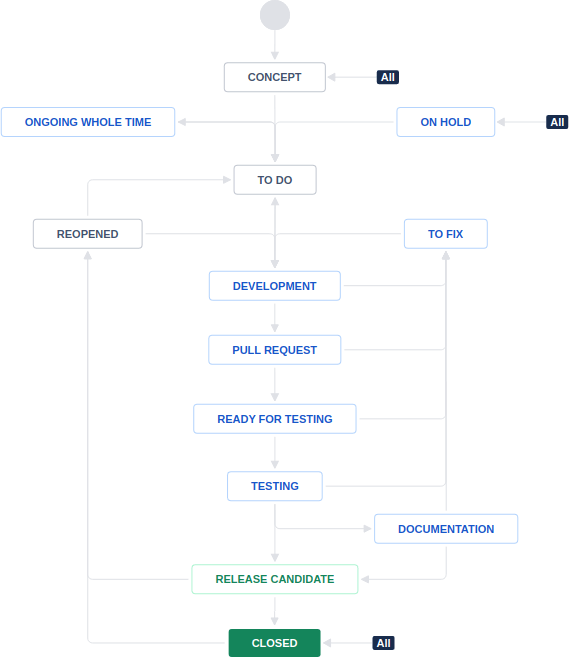
Firstly, it emphasizes the whole flow and when a task can get “moved back”. Secondly, it’s legible even on a phone, so it should be acceptable for everyone. Lastly, I felt that digging more into Jira’s configuration could be beneficial.
After receiving very positive feedback from the team, I craved more. The next target on my list was more automation – the less people have to interact with it, the better. We already had smart commits in place to link our branches, commits, and pull requests with Jira, but I wanted to bring it to the next level.
Around that time, Jira 9.0 was released, bringing an entirely new Automation feature. If you’ve ever used Zapier, Slack workflow builder, or even Scratch, you’ll feel at home – when a trigger happens, do some action. Sure, there are conditions and branching too, but that’s less important.
Again, I wanted to start small. The first automation was triggered when CI failed, and it moved the issue back to TO FIX status. It was live for a few days, and I quickly learned that it was not as simple as I first thought. The problem was that there was no validation, and if the issue was in a state that had no transition to this status. The automation simply failed, resulting in a sad email. One condition later, everything has worked smoothly for months now.
The next week I added a few more:
It took me less than a quarter to set up all of them, and it shaved off hours of work each month. It sounds crazy, but saving one minute every day for ten people sums up to more than three hours a month.
Not long later, together with the QA team, we added one to ease the release process, i.e., mark the issues as released, notify the watchers, etc. Then were some other ideas, like copying some fields to subtasks or setting assignees based on team preferences.
I love dashboards as much as I love curating them – sizes, labels, colors… All of it. Ranging from the objectively important ones, like a Cloud Watch one that summarizes the state of our application, to the subjectively important ones, like my weight trend. I’m serious about all of them. As Jira allows me to create dashboards, so why wouldn’t I give it a go?
The first one I made was too much – it had a list of tasks with far too many fields, statistics about the issue reporters, time spent on a project, and so on. It was neither useful nor easy on the CPU (it froze my browser once or twice). I had to focus and come up with something better.
The next version, which became our default one, consists of three lists of tasks: active (things the developer should focus on first, based on their status and priority), pre-development (coming up), and post-development (automatically cleaned up list of closed tasks). It may sound silly, but splitting it into three lists had an impact, as people found it easier to catch up with the priorities.
Some time ago, we were looking into how our software is doing based on the reported bugs. In other words, we wanted to know whether the closed bugs (we have an issue type for that) were actually bugs and not other things, e.g., misconfiguration on the user side or a duplicate report. Additionally, we’d like to group them by the area of the app they originated from.
After some digging, I found that the resolution field would be a good place for the former. For the latter, we’ve decided to add three custom fields with a list of predefined values for each. A quick check with filtering to confirm if it works, and there we have it. At least for the new issues.
But what about the others? Custom fields are fine, you can simply set their values, and that’s it (I highly recommend the bulk update for doing so). But the resolution field is so special that it requires a separate article to describe how to do it. Furthermore, it requires adding new transitions to your workflow as well as some post functions… It’s doable but far harder than it could be.
Everyone sees that we’ve improved our Jira setup significantly in the last year. More importantly, people know what we can do, and that we can iterate on the setup – workflow, views, labels, etc. I believe there’re still things we could do better, but I think we’ll get there eventually.
There are some limitations too. For example, if we’d like to react only on some CI checks we have and not all of them (e.g., exclude flaky E2E tests), we’d need to build a whole service just for syncing GitHub with Jira using webhooks.
This whole story felt just like my first time using Linux.